EMNLP Industry Track 2024 - Choi et al.
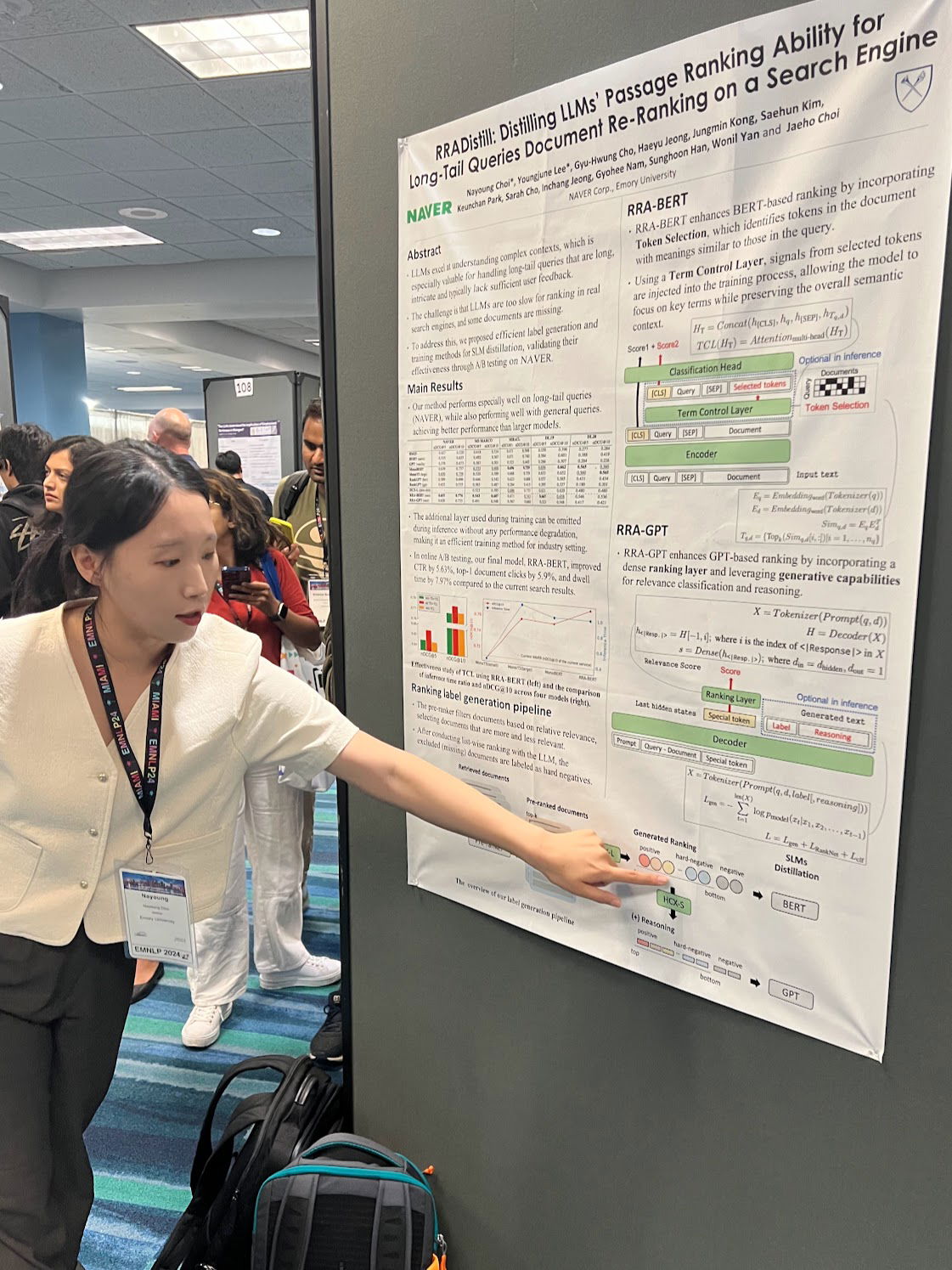
RRADistill: Distilling LLMs' Passage Ranking Ability for Long-Tail Queries Document Re-Ranking on a Search Engine
Nayoung Choi, Youngjune Lee, Gyu-Hwung Cho, Haeyu Jeong, Jungmin Kong, Saehun Kim, Keunchan Park, Jaeho Choi, Sarah Cho, Inchang Jeong, Gyohee Nam, Sunghoon Han, Wonil Yang
Abstract
Large Language Models (LLMs) excel at understanding the semantic relationships between queries and documents, even with lengthy and complex long-tail queries. These queries are challenging for feedback-based rankings due to sparse user engagement and limited feedback, making LLMs' ranking ability highly valuable. However, the large size and slow inference of LLMs necessitate the development of smaller, more efficient models (sLLMs). Recently, integrating ranking label generation into distillation techniques has become crucial, but existing methods underutilize LLMs' capabilities and are cumbersome. Our research, RRADistill: Re-Ranking Ability Distillation, propose an efficient label generation pipeline and novel sLLM training methods for both encoder and decoder models. We introduce an encoder-based method using a Term Control Layer to capture term matching signals and a decoder-based model with a ranking layer for enhanced understanding. A/B testing on a Korean-based search platform, validates the effectiveness of our approach in improving re-ranking for long-tail queries.
Venue / Year
Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) / 2024
Links
Anthology | Paper | Presentation | BibTeX